판다스 concat() 함수로 데이터프레임 합치기
먼저 같은 열이름과 행이름을 가진 데이터 프레임을 합치는 방법입니다.
일단 데이터를 로드해줍니다. 세 가지 데이터 모두 같은 형태를 취하고 있습니다.
import pandas as pd
df1 = pd.read_csv("concat_1.csv")
df2 = pd.read_csv("concat_2.csv")
df3 = pd.read_csv("concat_3.csv")

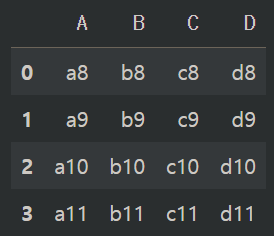
판다스의 "concat()" 함수를 사용해 3개 데이터를 합쳐보겠습니다. 기본은 언제나 열(컬럼, 시리즈) 단위로 되어 있기 때문에 컬럼명을 기준으로 아래로 붙어서 합쳐집니다.
# 세 개 데이터프레임 합치기
concat1 = pd.concat([df1, df2, df3])
인덱스를 기준으로 합치고 싶다면 역시 "axis=1" 옵션을 주면 됩니다.
# 데이터프레임 인덱스 기준으로 합치기
concat2 = pd.concat([df1, df2, df3], axis = 1)
만약 합쳐지면서 생긴 중복되는 인덱스나 컬럼명이 싫다면 "ignore_index=True" 옵션을 사용해 인덱스를 초기화시킬 수 있습니다.
# 컬럼명 초기화
concat3 = pd.concat([df1, df2, df3], axis = 1, ignore_index = True)
만약 초기화하지 않았다면 "reset_index()" 함수를 통해 초기화시켜줄 수도 있습니다. "inplace=True" 옵션은 원본을 수정한다는 의미이고 "drop=True" 옵션은 지금 있는 인덱스를 새로운 열로 가져오지 않고 그냥 버린다는 의미입니다.
concat1.reset_index(inplace = True, drop = True)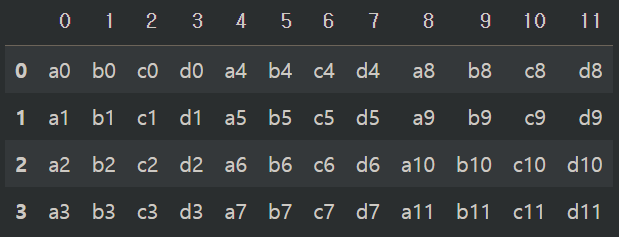
합쳐지는 데이터프레임에 기준이 되는 인덱스나 컬럼명이 다를 경우에도 합쳐집니다. 다만 서로 중복되지 않는 데이터는 'NaN' 처리됩니다.
# 인덱스 고치기
df2.index = ["a", "b", "c","d"]
#합치기
concat3 = pd.concat([df1, df2, df3], axis = 1)
판다스 merge를 사용해 데이터프레임 합치기
"concat()"이 인덱스와 컬럼명을 기준으로 단순하게 합치는 방식이라면, "merge()"는 특정 열의 값을 참조해 데이터프레임을 합칠 수 있는 방법입니다. DB를 다뤄보신 분들은 "join"의 기능이라고 생각하시면 될 듯합니다.
사용방법은 아래와 같습니다.
- df1.merge(df2, left_on = "df1 기준열", right_on = "df2 기준열")
먼저 데이터를 불러와봅니다.
site와 visited는 각각 "name - site"의 공통 키가 있고 servey와 visited는 "taken - ident"라는 공통점이 있습니다.
site = pd.read_csv("survey_site.csv")
servey = pd.read_csv("survey_survey.csv")
visited = pd.read_csv("survey_visited.csv")


먼저 site와 visited를 합쳐줍니다.
merge1 = visited.merge(site, left_on = "site", right_on = "name")
합쳐진 merge1에 servey를 합쳐줍니다.
merge2 = merge1.merge(servey, left_on = "ident", right_on="taken")
중복되는 열이 필요가 없다면 지워주면 됩니다.
merge1 = visited.merge(site, left_on = "site", right_on = "name")
merge2 = merge1.merge(servey, left_on = "ident", right_on="taken")
del merge2["name"]
del merge2["taken"]
merge() 에서 병합 옵션 사용하기
위와 같은 방식은 DB에서의 4가지 병합 방법 중 "inner join" 방식입니다. 데이터를 통해 알아보겠습니다.
df1 = pd.DataFrame([["A",0,0,0],["B",0,0,0],["C",0,0,0]], columns = ["std1", "a", "b", "c"])
df2 = pd.DataFrame([["A",0,0,0],["D",0,0,0],["F",0,0,0]], columns = ["std2", "d", "e", "f"])
두 데이터프레임을 "left join" 방식으로 붙여주면 왼쪽에 있는 데이터프레임에 있는 키만 붙여주고 나머지는 버립니다.
m = pd.merge(df1, df2, how="left", left_on = "std1", right_on = "std2")
"right join" 방식은 "left join"과 반대라고 보면 됩니다. 오른쪽이 기준이 됩니다.
m = pd.merge(df1, df2, how="right", left_on = "std1", right_on = "std2")
"outer join" 방식은 공통된 부분은 합쳐주고, 서로 없는 키도 넣어서 공통되지 않는 부분은 NaN값으로 합쳐주는 방식입니다. 두 데이터프레임의 모든 데이터가 들어가는 방식입니다.
m = pd.merge(df1, df2, how="outer", left_on = "std1", right_on = "std2")
반대로 "inner join"은 서로 공통된 키만 합쳐주고 나머지는 버립니다. 위에서 df1.merge(df2, ~) 방식이 이 방식으로 작동합니다.
m = pd.merge(df1, df2, how="inner", left_on = "std1", right_on = "std2")
위의 네 가지 조인 방법 중 상황에 맞도록 적절하게 사용해주면 됩니다.
'파이썬 > 라이브러리(API)' 카테고리의 다른 글
| 판다스 데이터프레임 행과 열 값 바꾸기 (0) | 2024.03.07 |
|---|---|
| 판다스 데이터 누락값(결측치) 처리하기 (0) | 2024.03.07 |
| 파이썬 시각화하기 - 맷플롯리브(matplotlib) 라이브러리 기초 (0) | 2024.03.07 |
| 판다스 데이터프레임에서 조건문(if문)으로 데이터 넣기 (2) | 2024.03.07 |
| 파이썬 판다스 Pandas 기본 문법 및 기초 사용법 (4) | 2024.03.06 |

댓글