열에 있는 값을 행으로 내리는 방법
판다스의 "melt()" 함수를 통해 간단히 수행할 수 있습니다. 먼저 데이터를 불러옵니다.
import pandas as pd
billboard = pd.read_csv("billboard.csv")
- pd.melt(데이터프레임, id_vars = ["남겨둘 컬럼"], var_name = "이동된 컬럼 이름", val_value = "값의 컬럼 이름")
한 번에 열의 값을 행으로 바꾸면 두 개의 컬럼이 새로 생기게 됩니다. 그대로 둘 컬럼과 함께 이름을 지정해줍니다. 가장 끝에 "week"와 "waiting" 컬럼이 추가된 것을 확인할 수 있습니다.
billboard2 = pd.melt(billboard, id_vars = ["year", "artist", "track", "time", "date.entered"],
var_name = "week", value_name = "waiting")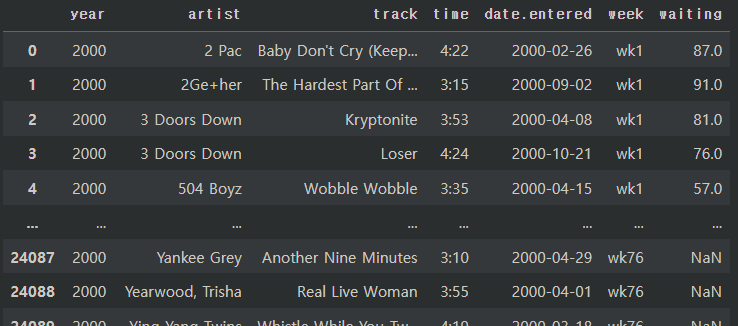
판다스 데이터프레임 컬럼 나누기
아래와 같이 데이터를 변형했는데 언더바("_")로 붙어 있는 단어의 컬럼을 두 개로 나눠야 하는 상황입니다.
country = pd.read_csv("country_timeseries.csv")
country2 = pd.melt(country, id_vars = ["Date", "Day"], var_name = "Cases", value_name = "count")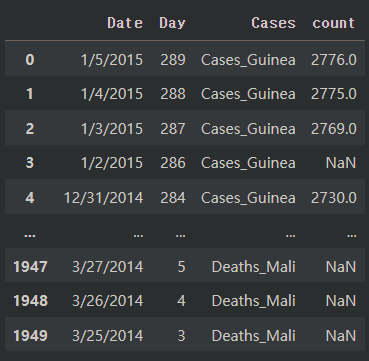
먼저 나눌 컬럼 "country2["Cases"]를 str 클래스를 써서 나눠줍니다. split()은 나눠진 문자열의 배열로 이루어진 시리즈를 반환합니다.
country3 = country2["Cases"].str.split("_")
여기서 문자열의 열에 접근하는 방법은 "country3.str[0] / country3.str[1]" 입니다.
새로운 컬럼을 만들어서 값을 삽입해줍니다. 잘 들어간 것을 확인할 수 있습니다. 필요없어진 "Cases" 컬럼은 del이나 drop을 통해 지워주면 됩니다.
country2["add1"] = country3.str[0]
country2["add2"] = country3.str[1]
행에 있는 값 열로 올리기
이번엔 행에 있는 값을 열로 올리는 작업입니다.
그냥 단순히 행을 열로 올리는게 아니라 엑셀의 피봇기능을 수행해줘서 데이터를 매우 깔끔하게 정리할 수 있습니다.
NaN값 또한 쉽게 처리 가능해 엑셀만큼 아주 유용한 기능을 제공합니다.
import pandas as pd
wheather = pd.read_csv("weather.csv")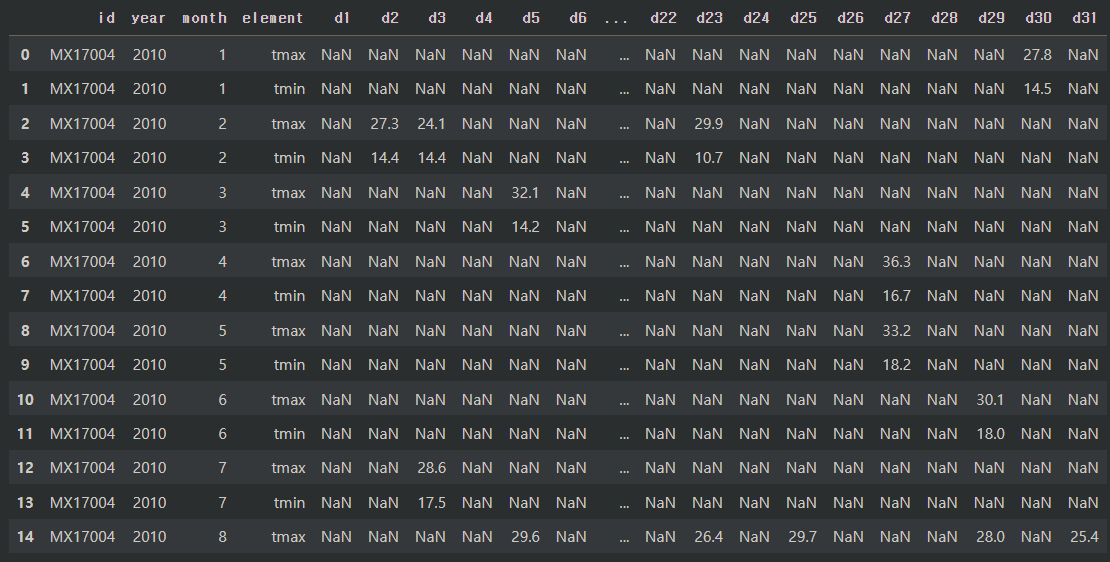
일단 딱 봐도 컬럼이 너무 많기 때문에 일단 melt()를 통해 컬럼 정리부터 해줍니다.
wheather2 = pd.melt(wheather, id_vars = ["id", "year", "month", "element"],
var_name = "day", value_name="temp")
엑셀 피봇을 생각해보면 위 자료에서 계속 중복되는 "tmax"와 "tmin" 값을 위로 올려주고 NaN값을 필터링해주면 깔끔하게 정리됩니다.
여기서도 마찬가지로 날짜별로 최대온도(tmax)와 최저온도(tmin)의 값(temp)을 편하게 보기 위해 피봇을 진행합니다.
"index" 옵션을 통해 행에 고정할 값을 선택하면 나머지는 알아서 위로 올라가 정리됩니다.
위로 올라가는 컬럼의 전체 이름을 "columns" 값으로 주고 tmax와 tmin이 가질 값인 "values"의 컬럼을 지정해줍니다.
마지막으로 "dropna" 옵션을 통해 NaN값은 자동으로 버리도록 하면 누락값에 대한 필터링까지 완성됩니다.
모양도 딱 엑셀 피봇같은 모양이 나오네요.
wheather3 = wheather2.pivot_table(index = ["id", "year", "month", "day", ],
columns = "element", values="temp", dropna = True)
좀 더 보기 좋은 데이터프레임으로 만들고 싶으면 인덱스를 초기화해주면 됩니다.
wheather3.reset_index(inplace = True)
문법 자체는 어려울게 없는데 아무래도 복잡한 데이터 구조를 어떻게 효율적으로 짜는가의 문제가 관건인 듯합니다.
'파이썬 > 라이브러리(API)' 카테고리의 다른 글
| 파이썬 인터넷 웹페이지 크롤링하기 (1) | 2024.03.09 |
|---|---|
| 파이썬 판다스 데이터에 순위 매기기 (0) | 2024.03.08 |
| 판다스 데이터 누락값(결측치) 처리하기 (0) | 2024.03.07 |
| 판다스 데이터프레임 합치기 (데이터프레임 병합) (1) | 2024.03.07 |
| 파이썬 시각화하기 - 맷플롯리브(matplotlib) 라이브러리 기초 (0) | 2024.03.07 |

댓글